Posts (page 33 of 43)
-
Escape from Normality Oct 2, 2012
John Carpenter fans know the only way you’ll escape from New York is if Snake Plissken is there to get you out. When it comes to web security, don’t bother waiting for Kurt Russell’s help. You’re on your own.
And if you’re dealing with escape characters in JavaScript strings, you’ll want to make sure your application is a maximum security environment.
Imagine an app with a search function. It takes a form field named
qand, instead of reflecting the search term in the field’s value, it updates thevalueattribute with a one-line JavaScript call. Normally, you’d expect an app to just rewrite the<input>field like so:<input id="searchResult" type="text" name="q" value="abc">It’s not necessarily a bad idea to update the element’s
valuewith JavaScript. Building HTML with string concatenation is a notorious vector for XSS. Writing the value with JavaScript might be more secure than rebuilding the HTML every time because the assignment avoids several encoding problems. This works if you’re keeping the HTML static and trading JSON messages with the server.On the other hand, if you move the server-side string concatenation from the
<input>field to a<script>tag, then you’ve shifted the XSS problem to a different vector. In our target app, the<input>field’s value was delimited with quotation marks (“). The JavaScript code uses apostrophes (‘) to delimit the string, as follows:<script> document.getElementById('searchResult').value = 'abc'; </script>Rather than strip apostrophes from the search variable’s value, the developers decided to escape them with backslashes. Here’s how it’s expected to work when a user searches for
abc'.document.getElementById('searchResult').value = 'abc\\'';Escaping the payload’s apostrophe preserves the original string delimiters, prevents the JavaScript syntax from being manipulated, and blocks HTML injection attacks – so it seems.
What if the escape is escaped? Perhaps by throwing a backslash of your own into a search term like
abc\\'.document.getElementById('searchResult').value = 'abc\\\\'';The developers caught the apostrophe, but missed the backslash. When JavaScript tokenizes the string it sees the escape working on the second backslash instead of the apostrophe. This corrupts the syntax, as follows:
// ⬇ end of string token value = 'abc\\\\''; // ⬆ dangling apostropheFrom here we just start throwing HTML injection payloads against the app. JavaScript interprets
\\as a single backslash, accepts the apostrophe as the string terminator, and parses the rest of our payload.https://web.site/search?q=abc**\\';alert(9)//**document.getElementById('searchResult').value = 'abc\\\\';alert(9)//';JavaScript’s semantics are lovely from an attacker’s perspective. Here’s an example payload using the String concatenation operator (
+) to glue thealertfunction to the value:https://web.site/search?q=**abc\\'%2balert(9)//**document.getElementById('searchResult').value = 'abc\\\\'+alert(9)//';Or we could try a payload that uses the modulo operator (
%) between the String and our alert.abc\\'%alert(9)//Maybe the developers added the
alertfunction to a denylist, e.g. a regex foralert\(, by checking for an opening parenthesis. In that case, call the function via thewindowobject’s property list. This makes it look like an innocuous string to naive regexes:abc\\'%window["alert"](9)//What happens if the denylist contained the word
alertaltogether? Build the string character by character:abc\\'window[String.fromCharCode(0x61,0x6c,0x65,0x72,0x74)](9)//By now we’ve turned an evasion of an escaped apostrophe into an exercise in obfuscation and filter bypasses. These examples focused on all the permutations of escape sequences in JavaScript strings. Check out the HIQR for more anti-regex patterns and JavaScript obfuscation techniques.

A few additional tips when defending against the payloads:
- In code reviews, be suspicious of string concatenation. Use safer methods to bind user-supplied data to HTML.
- If you create output encoding methods rather than relying on frameworks like React, make sure they match the DOM context where the data will be written.
- Normalize data before operating on it, whether this entails character set conversion, character encoding, substitution, or removal.
- Apply security checks after normalization, preferring inclusion lists over exclusion lists – it’s a lot easier to guess what’s safe than assume what’s dangerous.
Normalization is an important first step. Any time you transform data you should reapply security checks. Snake Plissken was never one for offering advice. Instead, think of The Hitchhiker’s Guide to the Galaxy and recall Trillian’s report as the Infinite Improbability Drive powers down (p. 61):
…we have normality, I repeat we have normality….Anything you still can’t cope with is therefore your own problem.
Good luck with normality and trying to correctly escape data. Security isn’t a certainty, but one thing is, at least according to Queen – there’s ”no escape from reality.”
-
My Zombie Incursion into Amazon.com Sep 21, 2012
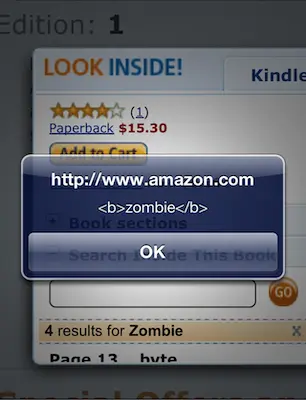
This is how the end began. Over two years ago I unwittingly planted the seeds of an undead outbreak into the pages of my book, Seven Deadliest Web Application Attacks.
Only recently did I discover the decaying fruit of those seeds festering within the pages of Amazon. The book had been translated into Korean and I was curious about the translation of a few sentences. So, I went to check a few words in the English version, which was easy to do on Amazon:
- Visit the book’s Amazon page.
- Click on the “Look Inside!” feature. (Although apparently no longer available for this title.)
- Use the “Search Inside This Book” feature to search for zombie.
- Cower before the approaching horde of flesh-hungry brutes – or just click OK a few times.
On page 16 of the book there is an example of an HTML element’s syntax that forgoes the typical whitespace used to separate attributes. The element’s name is followed by a valid token separator, albeit one rarely used in hand-written HTML. The printed text contains this line:
<img/src="."alt=""onerror="alert('zombie')"/>
The “Search Inside” feature lists the matches for a search term. It makes the search term bold (i.e. adds
<b>markup) and includes the context in which the search term was found (hence the surrounding text with the full<img/src="."alt="" />element). Then it just pops the contextual find into the list, to be treated as any other “text” extracted from the book.<img src="." alt="" onerror="alert('<b>zombie</b>')"/>Finally, the matched term is placed within an anchor so you can click on it to find the relevant page. Notice that the
<img>tag hasn’t been inoculated with HTML entities; it’s a classic HTML injection attack.<a ... href="javascript:void(0)"> <span class="sitbReaderSearch-result-page">Page 16 ...t require spaces to delimit their attributes. **<img src="." alt="" onerror="alert('<b>zombie</b>')"/>** JavaScript doesn't have to...(You can also use Google Books to see similar results, minus the XSS flaw.)
This has actually happened before. In December 2010 a researcher in Germany, Dr. Wetter, reported the same effect via
<script>tags when searching for content in different security books. He even found<script>tags whosesrcattribute pointed to a live host, which made the flaw infinitely more entertaining.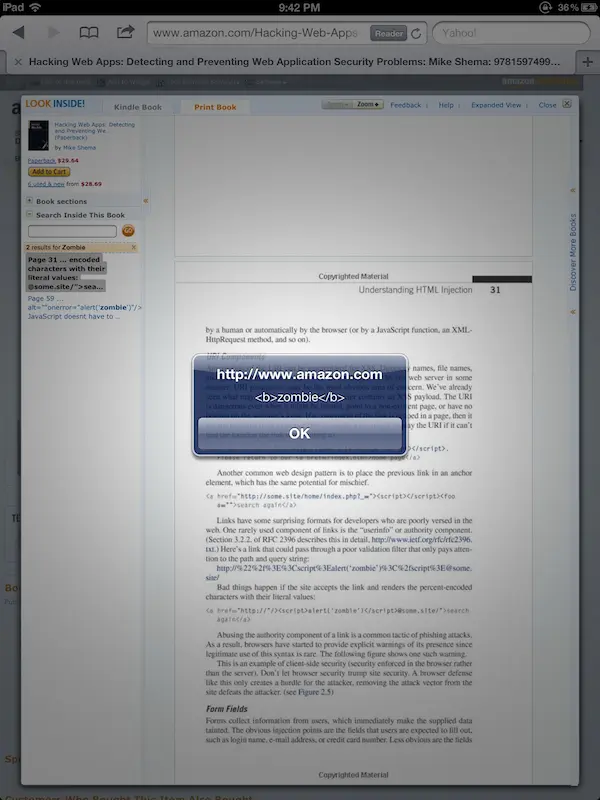
In fact, this was such a clever example of an unexpected vector for HTML injection that I included Dr. Wetter’s findings in the new Hacking Web Apps book (pages 40 and 41, the same
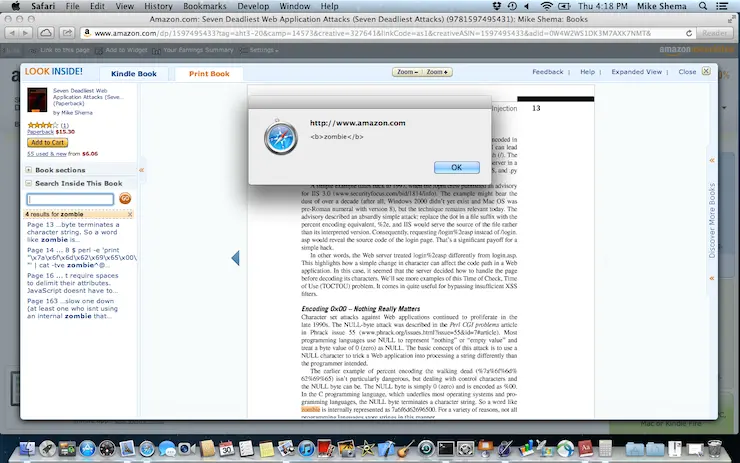
<img...onerror>example shows up a little later on page 59).Behold, there’s a different infestation on page 31 (see also the Google Books result). Try searching for zombie again. This time the server responds with a JSON object that contains
<script>tags. This one was harder to track down. The<script>tags don’t appear in the search listing, but they do exist in the excerpt property of the JSON object that contains the results of search queries:{...,"totalResults":2,"results":[[52,"Page 31","... encoded characters with their literal values: <a href=\"http://\"/>**<script>alert('<b>zombie</b>') </script>**@some.site/\">search again</a> Abusing the authority component of a ...", ...}I only discovered this injection flaw when I recently searched the older book for references to the living dead. (Yes, a weird – but true – reason.)
How did this happen?
One theory is that an anti-XSS filter relied on a deny list to catch potentially malicious tags. In this case, the
<img>tag used a valid, but uncommon, token separator that would have confused any filter expecting whitespace delimiters.One common approach to regexes is to build a pattern based on what we think browsers know. For example, a quick filter to catch
<script>tags or other opening tags like<iframe src...>or<img src...>might look like this – note the required space character:<\[\[:alpha:\]\]+(\\s+|>)A payload like
<img/src>bypasses that regex. The browser correctly parses its valid syntax to create an image element. Of course, thesrcattribute fails to resolve, which triggers theonerrorevent handler, leading to yet another banalalert()declaring the presence of an HTML injection flaw.The second
<script>-based example is less clear without knowing more about the internals of the site. Perhaps a sequence of stripping quotes plus poor regexes misunderstood thehrefto actually contain an authority section? I don’t have a good guess for this one.This highlights one problem of relying on regexes to parse a grammar like HTML. Yes, it’s possible to create strong, effective regexes. However, a regex does not represent the parsing state machine of browsers, including their quirks, exceptions, and “fix-up” behaviors.
Fortunately, HTML5 brings a degree of sanity to this mess by clearly defining rules of interpretation. On the other hand, web history foretells that we’ll be burdened with legacy modes and outdated browsers for years to come. So, be wary of those regexes.
Or maybe misusing regexes as parsers wasn’t the real flaw.
How did this really happen?
Well, I listen to all sorts of music while I write. You might argue that it was the demonic influence and Tony Iommi riffs of Black Sabbath that ensorcelled the book’s pages or that Judas Priest made me do it. Or that on March 30, 2010 – right around the book’s release – there was a full moon. Maybe in one of Amazon’s vast, randomly-stocked warehouses an oil drum with military markings spilled over, releasing a toxic gas that infected the books. We’ll never know for sure.
Maybe one day we’ll be safe from this kind of attack. HTML5 and Content Security Policy make more sandboxes and controls available for implementing countermeasures to HTML injection. But I just can’t shake the feeling that somehow, somewhere, there will always be more lurking about.
Until then, the most secure solution is to –
– huh, what’s that noise at the door…?
-
Password Interlude in D Minor Aug 27, 2012
While at least one previous post here castigated poor password security, a few others have tried to approach the problem in a more constructive manner. Each of these posts share fundamental themes:
-
Protect the password in transit from the threat of sniffers or intermediation attacks – Use HTTPS during the entire authentication process. HSTS is better. HSTS plus DNSSEC is best.
-
Protect the password in storage to impede the threat of brute force guessing – Never store the plaintext version of the password. Store the salted hash, preferably with PBKDF2. Where possible, hash the password in the browser to further limit the plaintext version’s exposure and minimize developers’ temptation or expectation to work with plaintext. Hashing affects the amount of effort an attacker must expend to obtain the original plaintext password, but it offers little protection for weak passwords. Passwords like p@ssw3rd or lettheright1in are going to be guessed quickly.
-
Protect the password storage from the threat of theft – Balance the attention to hashing passwords with attention to preventing them from being stolen in the first place. This includes (what should be) obvious steps like fixing SQL injection as well as avoiding surprises from areas like logging (such as the login page requests, failed logins), auditing (where password “strength” is checked on the server), and ancillary storage like backups or QA environments.
Implementing PBKDF2 for password protection requires two choices: an HMAC function and number of iterations. For example, WPA2 uses SHA-1 for the HMAC and 4,096 iterations. A review of Apple’s OS X FileVault 2 (used for full disk encryption) reveals that it relies in part on at least 41,000 iterations of SHA-256. RFC 3962 provides some insight, via example, of how to select an iteration count. It’s a trade-off between inducing overhead on the authentication system (authentication still needs to be low-latency from the user’s perspective, and too much time exposes it to easy DoS) versus increasing an attacker’s work effort.
A more sophisticated approach that I haven’t covered yet is the Secure Remote Password (SRP) protocol. SRP introduces a mechanism for password authentication and key exchange; becoming a more secure way to protect the authentication process from passive (e.g. sniffing) and active (e.g. replay, spoofing) attacks. However, the nature of browser security, especially the idea of crypto implemented in JavaScript, adds some interesting wrinkles to the practical security of SRP – not enough to dismiss SRP, just to understand how DNS, mixed-content, and JavaScript’s execution environment may have adverse effects. That’s a topic for another day.
Finally, sites may choose to avoid password management altogether by adopting strategies like OAuth or OpenID. Taking this route doesn’t magically make password-related security problems disappear. Rather than specifically protecting passwords, a site must protect authentication and authorization tokens; it’s still necessary to enforce HTTPS and follow secure programming principles. However, the dangers of direct compromise of a user’s password are greatly reduced.
The state of password security is a sad subject. Like D minor, which is the saddest of all keys.
-