We hope our browsers are secure in light of the sites we choose to visit. What we often forget, is whether we are secure in light of the sites our browsers choose to visit.
Sometimes it's hard to even figure out whose side our browsers are on.
Browsers act on our behalf, hence the term User Agent. They load HTML from the link we type in the address bar, then retrieve resources defined in that HTML in order to fully render the site. The resources may be obvious, like images, or behind-the-scenes, like CSS that styles the page's layout or JSON messages sent by XmlHttpRequest objects.
Then there are times when our browsers work on behalf of others, working as a Secret Agent to betray our data. They carry out orders delivered by Cross-Site Request Forgery (CSRF) exploits enabled by the very nature of HTML.
Part of HTML's success is its capability to aggregate resources from different origins into a single page. Check out the following HTML. It loads a CSS file, JavaScript functions, and two images from different origins, all over HTTPS. None of it violates the Same Origin Policy. Nor is there an issue with loading different origins from different TLS connections.
<!doctype html>
<html>
<head>
<link href="https://fonts.googleapis.com/css?family=Open+Sans" rel="stylesheet" media="all" type="text/css" />
<script src="https://ajax.aspnetcdn.com/ajax/jQuery/jquery-1.9.0.min.js"></script>
<script>$(document).ready(function() { $("#main").text("Come together..."); });</script>
</head>
<body>
<img alt="www.baidu.com" src="https://www.baidu.com/img/shouye_b5486898c692066bd2cbaeda86d74448.gif" />
<img alt="www.twitter.com" src="https://twitter.com/images/resources/twitter-bird-blue-on-white.png" />
<div id="main" style="font-family: 'Open Sans';"></div>
</body>
</html>
CSRF attacks rely on this commingling of origins to load resources within a single page. They're not concerned with the Same Origin Policy since they are neither restricted by it nor need to break it. They don't need to read or write across origins. However, CSRF is concerned with a user's context (and security context) with regard to a site.
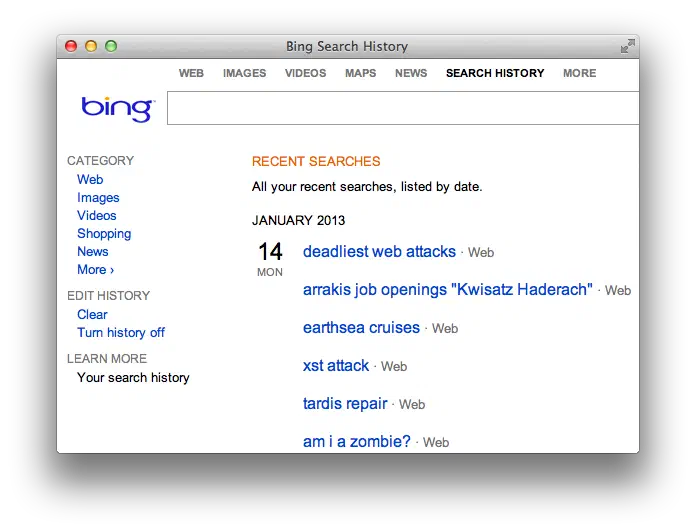
To get a sense of user context, let's look at Bing. Click on the Preferences gear in the upper right corner to review your Search History. You'll see a list of search terms like the following example:

Bing's search box is an <input> field with parameter name q. Searching for a term -- and therefore populating the Search History -- happens when the browser submits the form. Doing so creates a request for a link like this:
https://www.bing.com/search?q=lilith%27s+brood
In a CSRF exploit, it's necessary to craft a request chosen by the attacker, but submitted by the victim. In the case of Bing, an attacker need only craft a GET request to the /search page and populate the q parameter.
Forge a Request
We'll use a CSRF attack to populate the victim's Search History without their knowledge. This requires luring them to a page that's able to forge (as in craft) a search request. If successful, the forged (as in fake) request will affect the user's context -- their Search History.
One way to forge an automatic request from the browser is via the src attribute of an img tag. The following HTML would be hosted on some origin unrelated to Bing:
<!doctype html>
<html>
<body>
<img src="https://www.bing.com/search?q=deadliest%20web%20attacks" style="visibility: hidden;" alt="" />
</body>
</html>
The victim has to visit this web page or perhaps come across the img tag in a discussion forum or social media site. They do not need to have Bing open in a different browser tab or otherwise be using it at the same time they come across the CSRF exploit. Once their browser encounters the booby-trapped page, the request updates their Search History even though they never typed "deadliest web attacks" into the search box.
As a thought experiment, expand this scenario from a search history "infection" to a social media status update, or changing an account's email address, or changing a password, or any other action that affects the victim's security or privacy.
The key here is that CSRF requires full knowledge of the request's parameters in order to successfully forge one. That kind of forgery (as in faking a legitimate request) requires another article to better explore. For example, if you had to supply the old password in order to update a new password, then you wouldn't need a CSRF attack -- just log in with the known password. Or another example, imagine Bing randomly assigned a letter to users' search requests. One user's request might use a q parameter, whereas another user's request relies instead on an s parameter. If the parameter name didn't match the one assigned to the user, then Bing would reject the search request. The attacker would have to predict the parameter name. Or, if the sample space were small, fake each possible combination -- which would be only 26 letters in this imagined scenario.
Crafty Crafting
We'll end on the easier aspect of forgery (as in crafting). Browsers automatically load resources from the src attributes of elements like img, iframe, and script, as well as the href attribute of a link. If an action can be faked by a GET request, that's the easiest way to go.
HTML5 gives us another nifty way to forge requests using Content Security Policy directives. We'll invert the expected usage of CSP by intentionally creating an element that violates a restriction. The following HTML defines a CSP rule that forbids src attributes (default-src 'none') and a destination for rule violations. The victim's browser must be lured to this page, either through social engineering or by placing it on a commonly-visited site that permits user-uploaded HTML.
<!doctype html>
<html>
<head>
<meta http-equiv="X-WebKit-CSP" content="default-src 'none'; report-uri https://www.bing.com/search?q=deadliest%20web%20attacks%20CSP" />
</head>
<body>
<img alt="" src="/" />
</body>
</html>
The report-uri creates a POST request to the link. Being able to generate a POST is highly attractive for CSRF attacks. However, the usefulness of this technique is hampered by the fact that it's not possible to add arbitrary name/value pairs to the POST data. The browser will percent-encode the values for the document-url and violated-directive parameters. Unless the browser incorrectly implements CSP reporting, it's a half-successful technique at best.
POST /search?q=deadliest%20web%20attacks%20CSP HTTP/1.1
Host: www.bing.com
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_2) AppleWebKit/536.26.17 (KHTML, like Gecko) Version/6.0.2 Safari/536.26.17
Content-Length: 121
Origin: null
Content-Type: application/x-www-form-urlencoded
Referer: https://web.site/HWA/ch3/bing_csp_report_uri.html
Connection: keep-alive
document-url=https%3A%2F%2Fweb.site%2FHWA%2Fch3%2Fbing_csp_report_uri.html&violated-directive=default-src+%27none%27
There's far more to finding and exploiting CSRF vulns than covered here. We didn't mention risk, which in this example is low. There's questionable benefit to the attacker or detriment to the victim. Notice that you can even turn history off and the history feature is presented clearly rather than hidden in an obscure privacy setting.
Nevertheless, this Bing example demonstrates the essential mechanics of an attack:
- A site tracks per-user context.
- A request is known to modify that context.
- The request can be recreated by an attacker, i.e. parameter names and values are predictable.
- The forged request can be placed on a page where the victim's browser encounters it.
- The victim's browser submits the forged request and affects the user's context.
Later on, we'll explore attacks that affect a user's security context and differentiate them from nuisance attacks or attacks with negligible impact to the user. We'll also examine the forging of requests, including challenges of creating GET and POST requests. Then explore ways to counter CSRF attacks.
Until then, consider who your User Agent is really working for. It might not be who you expect.
Finally, I'll leave you with this quote from Kurt Vonnegut in his introduction to Mother Night. I think it captures the essence of CSRF quite well.
We are what we pretend to be, so we must be careful about what we pretend to be.